

How well can large language models predict the future?
We’ve just released an updated version of ForecastBench, our LLM forecasting benchmark. Here’s what the new results reveal about the accuracy of state-of-the-art models.

Post written by Houtan Bastani, Simas Kučinskas, and Ezra Karger.1
When will artificial intelligence (AI) match top human forecasters at predicting the future? In a recent podcast episode, Nate Silver predicted 10–15 years. Tyler Cowen disagreed, expecting a 1–2 year timeline. Who’s more likely to be right?
Today, the Forecasting Research Institute is excited to release an update to ForecastBench—our benchmark tracking how well large language models (LLMs) forecast real-world events—with evidence that bears directly on this debate. We’re also opening the benchmark for submissions.
Here are our key findings:
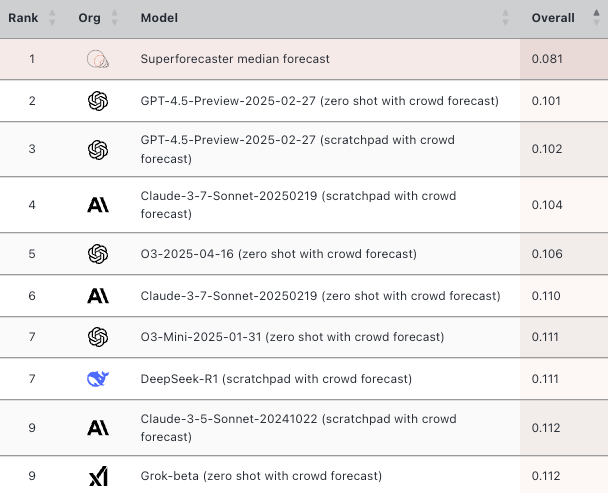
Superforecasters still outperform leading LLMs, but the gap is modest. The best-performing model in our sample is GPT-4.5, which achieves a Brier score of 0.101 versus superforecasters’ 0.081 (lower is better).2
LLMs now outperform non-expert public participants. A year ago, the median public forecast ranked #2 on our leaderboard, right behind superforecasters and ahead of all LLMs. Today it sits at #22. This achievement represents a significant milestone in AI forecasting capability.
State-of-the-art LLMs show steady improvement, with projected LLM-superforecaster parity in late 2026 (95% CI: December 2025 – January 2028). Across all questions in our sample, LLM performance improves by around 0.016 Brier points per year. Linear extrapolation suggests LLMs could match expert human performance on ForecastBench in around a year if current trends continue.
1. Why measure LLM forecasting accuracy?
Measuring LLM forecasting ability matters for three reasons:
Powerful testbed for LLM reasoning capabilities. Like coding or mathematics, accurate forecasting demands multiple cognitive skills—data gathering, causal reasoning, probabilistic thinking, and information synthesis. We think these features make forecasting a valuable proxy for general intelligence.
High practical value. We constantly make predictions, from everyday decisions (“Should I take an umbrella?”) to high-stakes business planning (“What will next quarter’s revenue look like?”). If LLMs can expand access to high-quality forecasting or improve human judgment, they could transform decision-making.
Future-only, hard to game. Unlike other LLM benchmarks that suffer from data contamination, forecasting requires predicting events that have not yet happened. Future outcomes cannot exist in any training dataset. Accurate LLM predictions of the future are a signal of genuine capability, rather than data leakage or memorization.
2. How ForecastBench works
ForecastBench evaluates LLMs by regularly asking them to make probabilistic forecasts about future events.
We use two types of binary prediction questions:
Dataset questions (250 questions each round): Automatically generated from real-world time series (ACLED, DBnomics, FRED, Yahoo! Finance, and Wikipedia) using pre-specified templates. Example questions from the September 28, 2025 forecasting round:
“According to Wikipedia, will Summer McIntosh still hold the world record for 400m individual medley in long course (50 metres) swimming pools on 2025-10-28”? (based on Wikipedia)
“Will there be more ‘Riots’ in the Philippines for the 30 days before 2025-12-27 compared to the 30-day average of ‘Riots’ over the 360 days preceding 2025-09-28?” (based on ACLED)
“Will the Federal Reserve Bank of Cleveland’s 30-year expected inflation rate have increased by 2026-09-28 as compared to its value on 2025-09-28?” (based on FRED).
Market questions (250 questions each round): Drawn from leading prediction platforms (Manifold, Metaculus, Polymarket, and Rand Forecasting Initiative). Example questions from the September 28, 2025 forecasting round:
“Will hostilities between Pakistan and India result in at least 100 total uniformed casualties (with at least one death) between 2 June 2025 and 30 September 2025?” (RAND Forecasting Initiative)
“Will a human step foot on Mars by 2030?” (Manifold)
“Will the CDC report 10,000 or more H5 avian influenza cases in the United States before January 1, 2026?” (Metaculus)
To construct the leaderboard, we equally weight performance on market and dataset questions. We calculate accuracy scores separately for each question type, then average them.
ForecastBench operates as a fully automated, dynamic system. New forecasting rounds occur biweekly. The leaderboard and datasets are updated nightly as questions resolve, allowing us to continuously track forecasting performance.
Prompting. LLMs currently use either zero-shot or scratchpad prompts (see repository). Dataset questions include the current value of the relevant metric (e.g., world record holder, recent event count, expected inflation rate) and an explanation of that value. For market questions, Baseline models receive no market forecasts, while Tournament models receive the current market forecast.3
3. Updates to ForecastBench
New ranking methodology
ForecastBench initially used standard Brier scores to rank forecasters. This approach worked when all forecasters—humans and LLMs—predicted the same questions. However, this method breaks down with imperfect question overlap, i.e., when forecasters answer different sets of questions.
To solve this problem, we developed the difficulty-adjusted Brier score. We adjust raw Brier scores based on each question’s difficulty, with question difficulty estimated via market Brier scores for market questions and a two-way fixed effects model for dataset questions. Poor performance on hard questions gets smaller penalties; good performance on easy questions earns less credit. This lets us fairly compare any two forecasters, even if they predicted completely different questions. For methodological details, see our technical report.
Baseline and Tournament leaderboards
We now maintain two leaderboards:
Baseline: Tracks out-of-the-box LLM forecasting performance (i.e., no scaffolding, fine-tuning, or external tools). This leaderboard isolates the improvement of pure model capabilities over time.
Tournament: Tracks frontier accuracy by allowing any enhancement, including scaffolding, fine-tuning, ensembling, or tool use. The leaderboard is now open to public submissions.4
Other changes
We’ve made several other changes to ForecastBench (see the changelog for the full list). Most importantly, we wait 50 days before adding new models to the leaderboard. Our analysis shows we need around 50 days of predictions to reliably estimate performance. For example, OpenAI’s GPT-5, which first participated in the 2025-08-31 round, will appear on the leaderboard on October 20, 2025.
4. Key Insights
Our updated benchmark reveals four main insights into the state of LLM forecasting.
Insight 1: Superforecasters still outperform all models
Superforecasters maintain their position at the top of our Tournament leaderboard, with a difficulty-adjusted Brier score of 0.081 (lower scores are better). The best-performing LLM on our leaderboard currently is GPT-4.5, achieving a score of 0.101.
How significant is this 0.02 gap between superforecasters and GPT-4.5? Here are three ways to interpret it:
Relative performance: GPT-4.5’s Brier score is 25% higher (i.e., worse) than superforecasters’.
Distance from baseline: Always predicting 50% yields a Brier score of 0.25; perfect prediction yields 0. Hence, superforecasters capture 68% of the possible improvement, while GPT-4.5 achieves 60%, or 8 percentage points less.
Model generations: The 0.02 gap is smaller than the 0.03-point improvement from GPT-4 to GPT-4.5, suggesting the distance to superforecasters is less than one major model generation.
While superforecasters maintain their edge, the gap is modest. In addition, as we show below, the gap is shrinking steadily.
Insight 2: LLMs have surpassed the general public
A year ago, the median public forecast ranked #2, trailing only superforecasters. Today, that same public benchmark sits at #22, with multiple LLMs now outperforming it.
This change represents a significant milestone: leading AI systems now forecast better than non-expert humans, even though LLMs still fall short of frontier human performance.
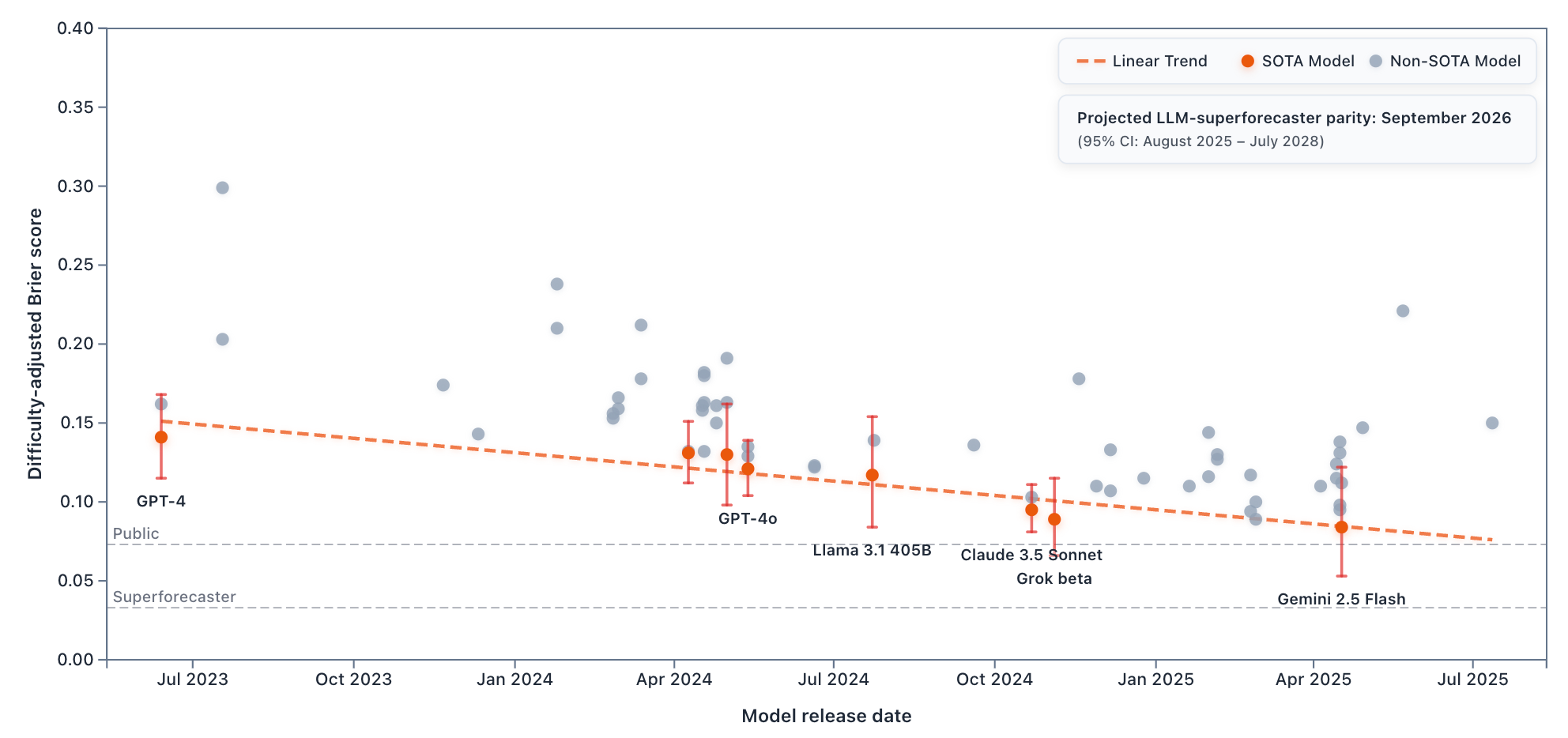
Insight 3: LLM forecasting improves steadily
The data reveals consistent improvement in state-of-the-art LLM forecasting performance:
GPT-4 (released in March 2023) achieved a difficulty-adjusted Brier score of 0.131. Nearly two years later, GPT-4.5 (released in February 2025) scores 0.101—a large improvement.
We estimate that state-of-the-art LLM performance improves by approximately 0.016 difficulty-adjusted Brier points annually. Linear extrapolation suggests LLMs will match superforecaster performance on ForecastBench in November 2026 (95% CI: December 2025 – January 2028).
Insight 4: LLM accuracy varies across question types, with predictable improvement on both
Performance patterns differ substantially between dataset and market questions, though superforecasters lead on both question types.
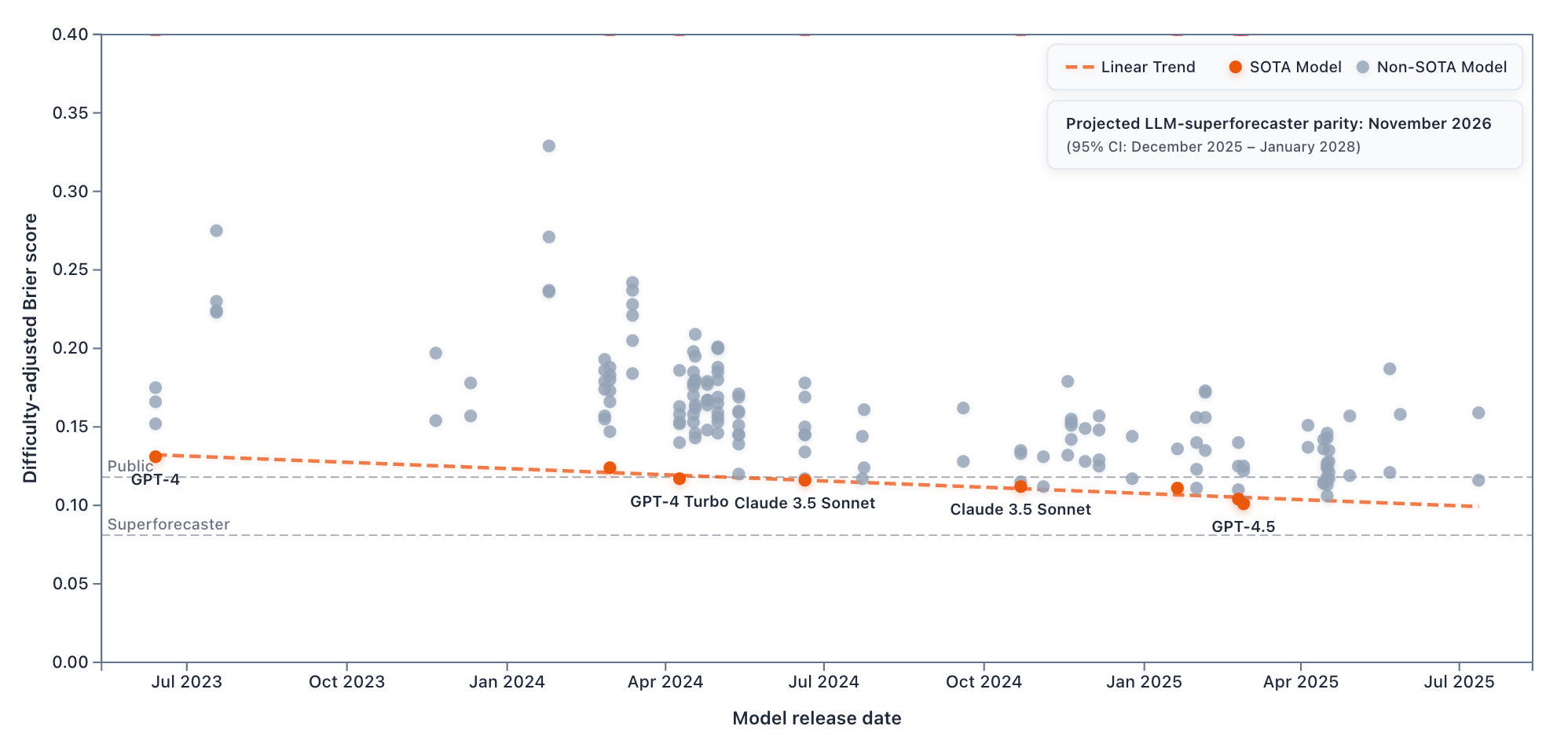
For dataset questions, OpenAI’s o3 leads among the LLMs in our sample. LLMs are improving by 0.020 Brier points annually, with parity projected for June 2026 (95% CI: November 2025 – April 2027).
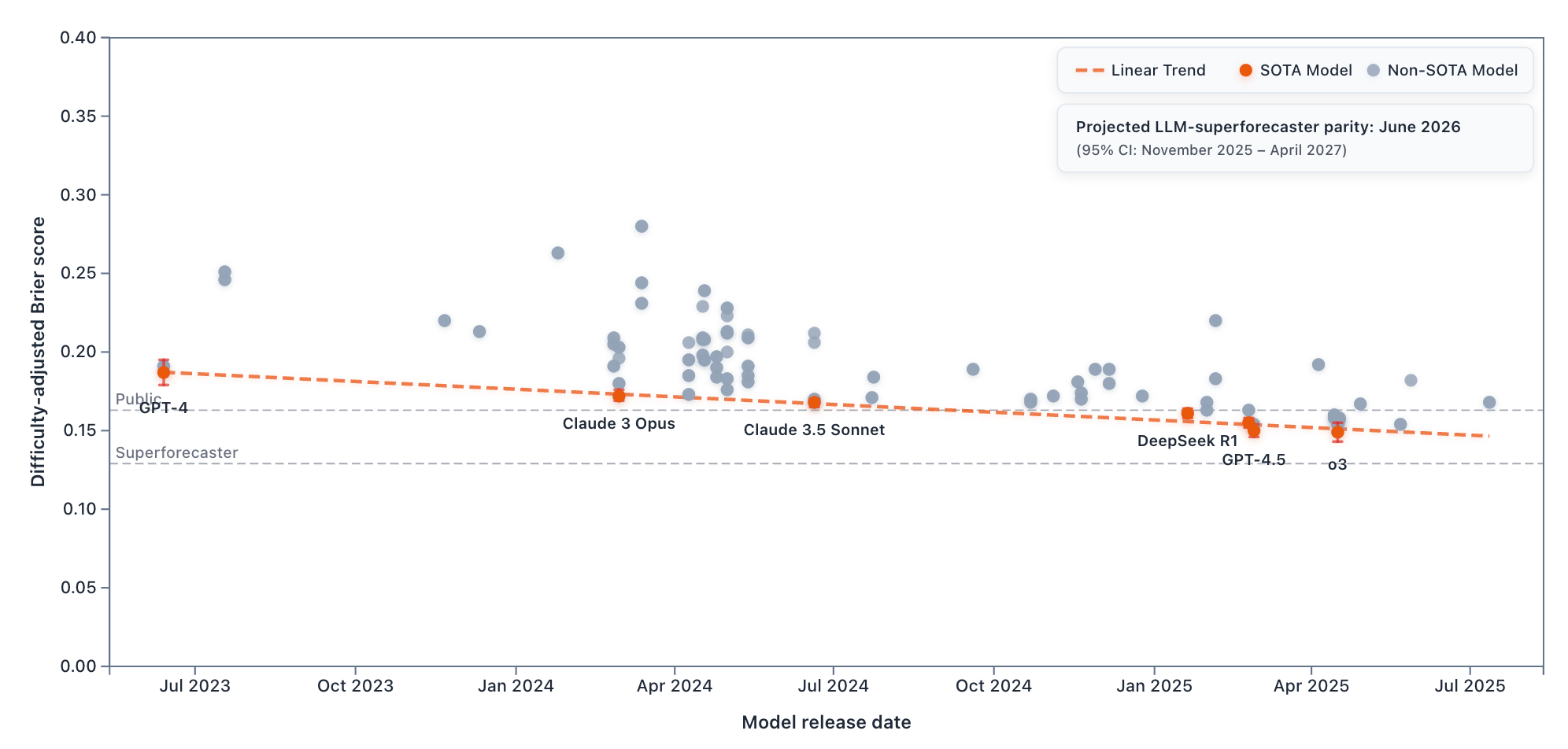
For market questions, GPT-4.5 performs best. However, some market results are surprising. First, GPT-4.5 tops the market leaderboard, although it was released in February 2025, and multiple newer models have appeared on ForecastBench since then. Second, while the projected parity date for market questions is similar to dataset questions (March 2026; 95% CI: March 2025 – December 2028), the rate of progress is slower, at 0.015 Brier points annually.
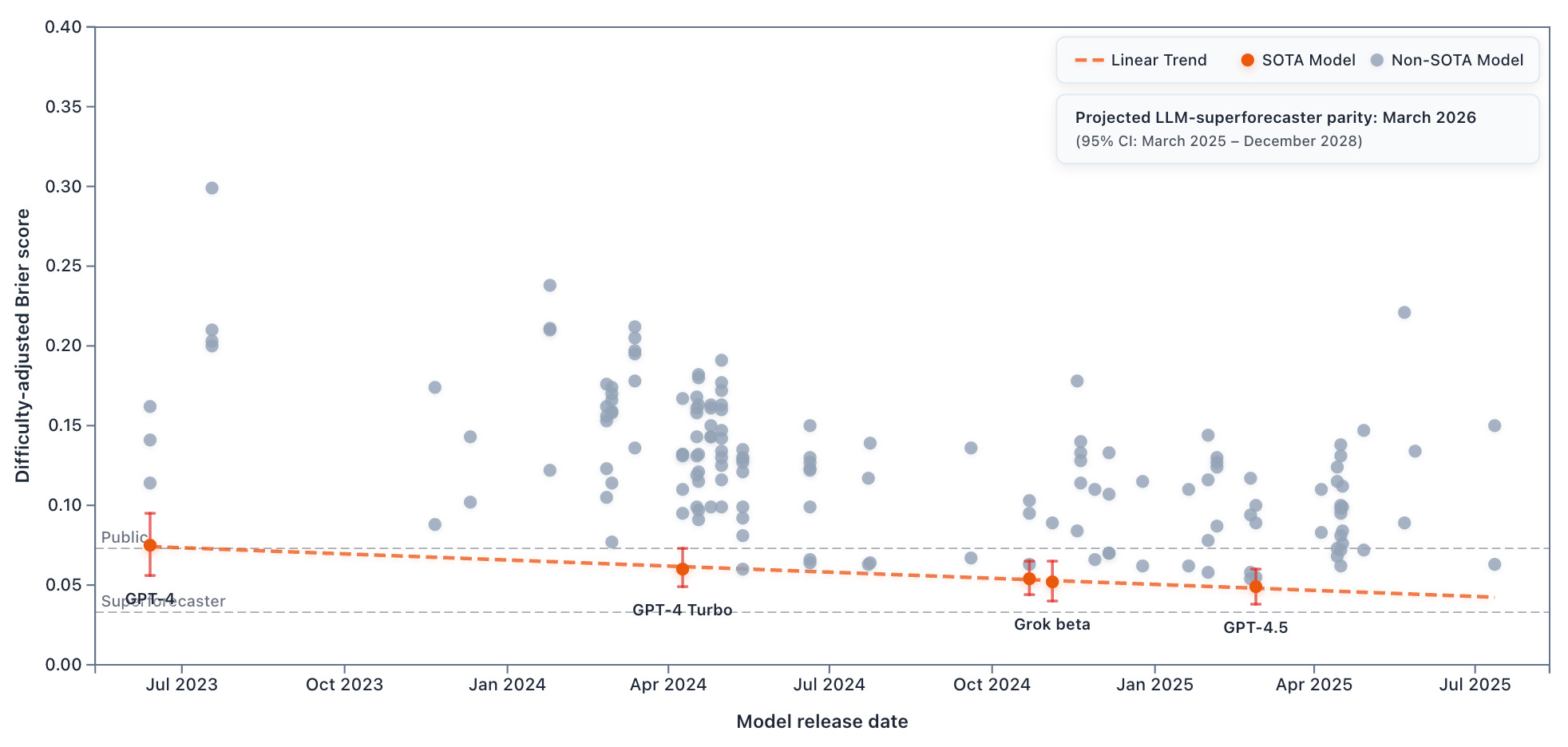
The reason for these surprising results: LLMs have discovered a shortcut. When provided market forecasts in their prompts, multiple LLMs—including GPT-4.5—simply copy them. GPT-4.5’s predictions have a correlation of 0.994 with provided market forecasts, and it submitted exact market values for 26 out of 122 questions, with a median deviation of just 0.5 percentage points. Since prediction markets are highly accurate, this tactic works but reveals little about underlying capabilities.5
The Baseline leaderboard tells the real story on market questions. Without access to market forecasts or external tools, LLMs cannot just copy-paste and must generate predictions independently. Here, improvement accelerates to 0.036 Brier points annually:
In summary, LLMs show consistent progress on both question types when measured properly.
5. Comparison to other forecasting benchmarks
The landscape of LLM forecasting benchmarks is expanding rapidly, with several benchmarks attempting to measure LLMs’ ability to predict future events:
Relative to other benchmarks, ForecastBench has several key advantages:
Dynamic and continuous. With biweekly forecasting rounds and nightly resolution updates, ForecastBench operates continuously with minimal manual input. This sustainability ensures long-term tracking of AI progress.
Methodological innovation for fair comparison. Our difficulty-adjusted Brier score solves the fundamental challenge of fairly comparing models released months or years apart.
Comprehensive human baselines. Unlike most alternatives, ForecastBench includes both expert (superforecasters) and non-expert (educated public) human baselines. These baselines allow us to not only rank different LLMs, but also measure whether LLMs can match average or expert-level human performance.
No data contamination. Only predictions of future events—which by definition cannot be included in any training dataset—are included in ForecastBench. We do not backfill predictions or ask models to predict on already-resolved questions.
Diverse, large-sample question set. At 500 questions per round, ForecastBench achieves substantial scale while maintaining question diversity by combining prediction market questions with automatically-generated dataset questions.
6. Limitations
Some limitations of our work should be kept in mind when interpreting the results:
Limited question overlap limits ranking confidence. Our difficulty-adjusted Brier score methodology enables fair comparison across models. However, the ranking’s confidence decreases with limited question overlap. GPT-4.5, released in February 2025, shares no questions with superforecasters who participated in July 2024. Their relative performance is therefore fully extrapolated through intermediate models.
Current results likely underestimate LLM potential. The LLMs in ForecastBench use basic prompting without access to news. By keeping prompting constant, ForecastBench isolates improvements in core model capabilities from advances in prompting techniques. However, models with sophisticated prompting strategies, fine-tuning, or real-time information access would likely perform better.
Only binary forecasting questions. ForecastBench currently only includes binary “yes/no” questions. This excludes point predictions for continuous variables (“What will the GDP growth rate be?”), multiple-choice outcomes (“Which party will win the election in Germany?”), quantile predictions (“What is the 95th percentile for the 7-day change in Apple’s stock price?”), and full probability distribution (“Provide a probability density function for next quarter’s inflation rate”) elicitation. As a result, ForecastBench is limited in the scope of forecasting capabilities that it can evaluate.
7. Takeaways
So who was right—Nate Silver with his 10–15 year timeline, or Tyler Cowen with his 1–2 year prediction?
Our data suggests Cowen is closer to the mark. At the current rate of improvement, LLMs would match superforecaster performance by late 2026. Even if progress slows or plateaus, the current gap is narrow enough that LLMs could close it soon.
Many factors could complicate this timeline. Linear extrapolation may break down as systems approach frontier performance—the last mile might prove hardest. Superforecasters may improve their accuracy, including by use of LLMs. Finally, our benchmark captures only one slice of forecasting ability: binary predictions on specific question types. Superforecasters may still maintain their edge on other, more complex forecasting questions.
ForecastBench will continue tracking the race between human and machine forecasting ability. As new models emerge and existing ones improve, our benchmark provides the empirical foundation for understanding when AI matches expert human performance. Whether that moment arrives in one year or ten, we’ll be measuring progress every step of the way.
8. Submit your model
🚀 The Tournament leaderboard is now open for submissions.
We evaluate any approach—from better prompting to novel architectures. Your model gets reliably benchmarked against state-of-the-art LLMs and human superforecasters using our difficulty-adjusted scoring. New questions every two weeks provide your models with continuous evaluation. Setup is straightforward: email us for access, download the question set, forecast, and upload your predictions.
Any questions? Email us at forecastbench@forecastingresearch.org.
Houtan Bastani and Simas Kučinskas contributed equally.
Models require 50 days of predictions before leaderboard inclusion (see details below in Section 3). Hence, new models are coming soon. For example, GPT-5 will be added on October 20, 2025.
For most questions, the current value reflects data from 10 days before the forecast due date.
Most of the results reported in this blog post are from the Tournament leaderboard.
This copying strategy is actually suboptimal. We provide market values from the “freeze date” (i.e., date when questions are generated), typically 10 days before the forecast submission deadline. LLMs could improve by simply checking current market values at submission. This also reveals a deeper measurement challenge. As LLMs become more capable, they could autonomously search for information—including finding relevant prediction markets—without being explicitly prompted. Such emergent agentic behavior would blur the line between the Baseline and Tournament leaderboards.
So happy to see you’ve started a Substack to more widely share your great work!
Questions: what happens when you extremize the public and super forecasts, rather than using the median? And when you also do that that with forecasts with multiple LLMs?