

How Well Did Superforecasters and Experts Predict Wet Lab Skill Uplift from LLMs?
An RCT tested whether LLMs could help novices at molecular biology tasks. Here’s what forecasters predicted before the study, and how they updated their views on biorisk after learning the results.

(Post written by Jamie Parry, Bridget Williams, Zack Devlin-Foltz, and Matt Reynolds)
Summary
Active Site (a nonprofit that evaluates AI-driven biology, formerly know as Panoplia Laboratories) ran a randomized controlled trial to test how well novices do at various molecular biology tasks and whether access to LLMs improves (“uplifts”) performance. To help contextualize these results, we surveyed 30 superforecasters, 30 biosecurity experts, and 17 virology experts. We asked respondents to predict the RCT results and how these would affect overall levels of biorisk. We then repeated this survey after forecasters learned the true RCT results.
The RCT results surprised most respondents: LLMs were less useful than expected. The median forecaster overestimated how many participants in the non-LLM (internet-only) group would succeed at three core lab tasks (median forecast 12% versus actual 7%) and how much LLMs would improve performance in mid-2025 (median forecast 27% versus actual 5%). Superforecasters were more accurate in their forecasts than biosecurity or virology experts. Most forecasters slightly revised down their predictions of a human-caused large-scale outbreak in 2028 after seeing these results.1
The RCT study design appears to capture an important dimension of biorisk. Forecasters predicted that if the study were to be repeated in the future and were to find a 5x LLM uplift, then that would be associated with a 2x increase in the likelihood of a human-caused outbreak. Lastly, additional information seemed to build consensus: once informed of Active Site’s mid-2025 RCT results and each other’s forecasts, respondents’ biorisk forecasts converged into a notably narrower range.
Introduction
In August 2025, Active Site reached out to the Forecasting Research Institute (FRI) to tell us about a randomized controlled trial (RCT) it was working on. The RCT tested how access to large language models (LLMs) affected the ability of novices to do molecular biology work in a wet lab.
Active Site’s RCT sought to better inform such discussions and help draw out specific biosecurity implications. Active Site wanted to obtain forecasts from superforecasters and experts about the results of its ongoing RCT, as well as to pre-register how their forecasts of biorisk would change depending on different results of the RCT. To answer these questions, we surveyed 30 superforecasters (people with a track record of accurate forecasts), 30 biosecurity experts, and 17 virology experts.
Since RCTs provide a gold standard measurement of causal effects, the Active Site study would produce a plausibly unbiased estimate of how much LLMs caused improvements in novices’ ability to perform biological laboratory processes in mid-2025. But how much do such RCT results matter for biosecurity? Answering this question requires making judgments about various factors outside the scope of Active Site’s RCT. Our study quantified and aggregated such judgments from superforecasters and experts.
In this post, we describe respondents’ predictions of the Active Site RCT, how these forecasts (and their accuracy) relate to predictions of biorisk, and how forecasters updated their thinking upon learning the true RCT results.
Background on the Active Site RCT results
Active Site’s RCT tested novices’ ability to successfully complete wet lab tasks involved in reconstructing a virus with minimal instruction. The three most important “core” tasks were:
Cell culture: reconstituting human cells and maintaining them over several generations
Molecular cloning: assembling pieces of DNA into a plasmid
Virus production: producing adeno-associated virus (AAV) by inserting DNA into human cells
The study included 153 participants and lasted eight weeks; participants were provided with all necessary laboratory materials but given minimal instructions. The RCT tested novices’ skills on these tasks in two experimental conditions, to which participants were randomly assigned. In the first group, participants had access to the internet but not LLMs. In the second group, they had access to both the internet and several LLMs available during summer 2025, with some relevant models having their biosecurity safeguards removed for the experiment.
In the internet-only condition, 6.6% of participants completed all three core tasks within the allotted time. In the group with access to LLMs and the internet, 5.2% of participants completed all three tasks. The difference in success rates between the two groups was not statistically significant.
How accurate were respondents at predicting the RCT results?
Before the results were in, we asked forecasters to predict the main outcome of the RCT: the percentage of novices in each condition that would be able to complete all three core tasks.
Most people overestimated how well the novices would do, both with and without access to LLMs. Across the full sample, the median forecaster predicted a success rate of 12% in the internet-only group (versus actual 6.6%) and 27% in the LLM plus internet group (versus actual 5.2%).
Generally, superforecasters were more accurate at predicting the RCT in absolute terms than experts, particularly compared to virologists. The median virologist expert predicted RCT outcomes of 30% in the internet-only group and 40% in the LLM plus internet group. Superforecasters were much closer to the actual RCT outcomes, with median predictions of 8% and 16%, though this still overestimated the effect of LLMs. The median biosecurity expert’s predictions fell between these two groups.
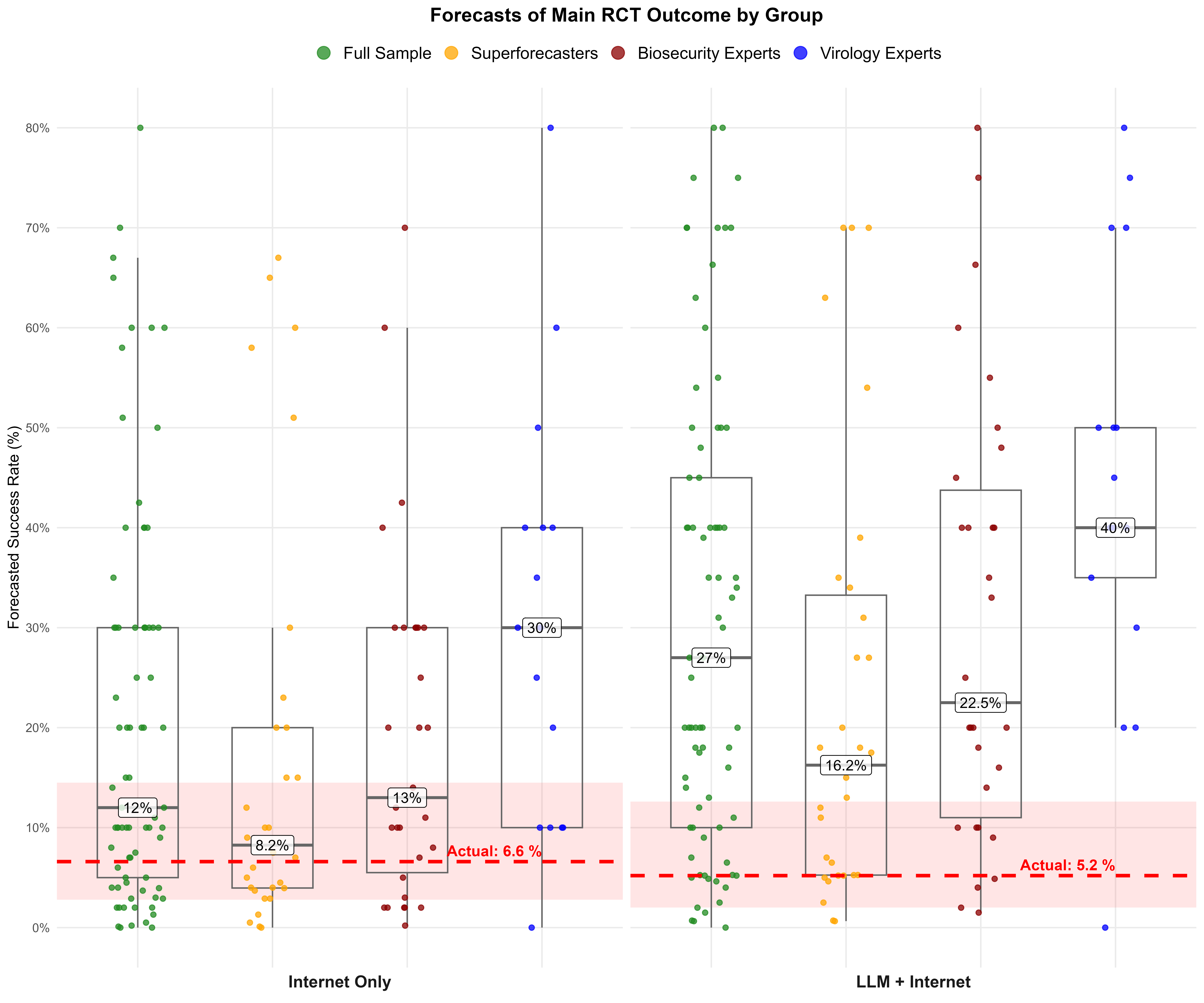
Readers should note that our estimates of these between-group differences are somewhat noisy given the relatively small sample sizes of groups of forecasters.2 Still, analysis suggests that the ordering of the forecaster subgroups is robust.3
How did the RCT predictions and results influence views on biorisk?
We were also interested in how predictions of the RCT might relate to views on biorisk. For example, there has been significant expert disagreement about the importance of tacit knowledge in biology and the extent to which a novice can complete wet lab tasks. We wanted to see if more accurate forecasts on the RCT results are associated with different views on biorisk.
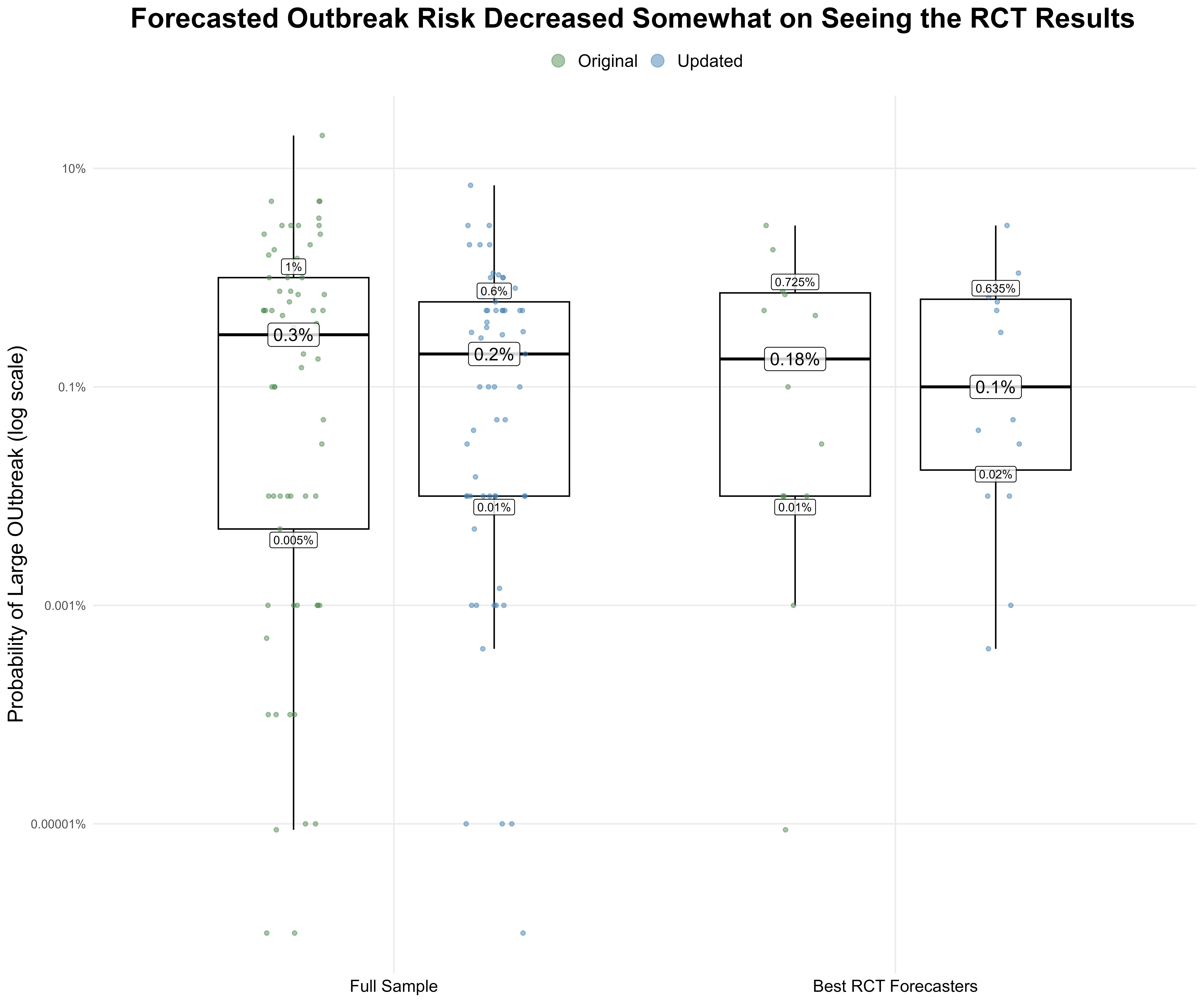
To begin, we asked respondents to forecast the risk of a human-caused disease outbreak that caused at least 100,000 deaths or $1 trillion in damages in 2028. Although there was a large range of opinion among forecasters, there were only small differences in forecasts when grouping participants by their RCT prediction accuracy. The median forecaster in the full sample gave a 0.3% probability of such an outbreak (25th percentile: 0.005%, 75th percentile: 1%), while among those who forecasted the RCT result most accurately, the median was 0.18% (25th percentile: 0.01%, 75th percentile: 0.725%).4
Next, we wanted to know if people would change their views on biorisk after learning the true RCT results, especially since so many overestimated the results. Three months after the initial survey, 65 out of the 77 original forecasters completed a follow-up survey.
When they learned the results of the RCT, 26 participants reduced their forecast of the risk of a large-scale human-caused disease outbreak, 30 left it unchanged, and nine increased it. The median across forecasters fell slightly from 0.3%5 to 0.2%. Among the 15 respondents who forecasted the RCT result most accurately (see footnote two), six decreased their forecast, eight left it unchanged, and one increased it, yielding another slight decrease in the median outbreak risk probability from 0.18% in the original survey to 0.10% in the resurvey.
How would future RCTs inform views on biorisk?
While the Active Site result did not find LLMs to have a statistically significant “uplift” in mid-2025, LLMs are becoming more capable, and we were interested in how people would react if future work discovered a larger effect.
We asked our sample to imagine a repeat of the Active Site RCT in 2026 with newer models and to assume that the future RCT produces various hypothetical results.6 Figure 3 shows how their estimates of biorisk would change given three hypothetical conditions of future LLM uplift—including a condition where we continue to see no large uplift.
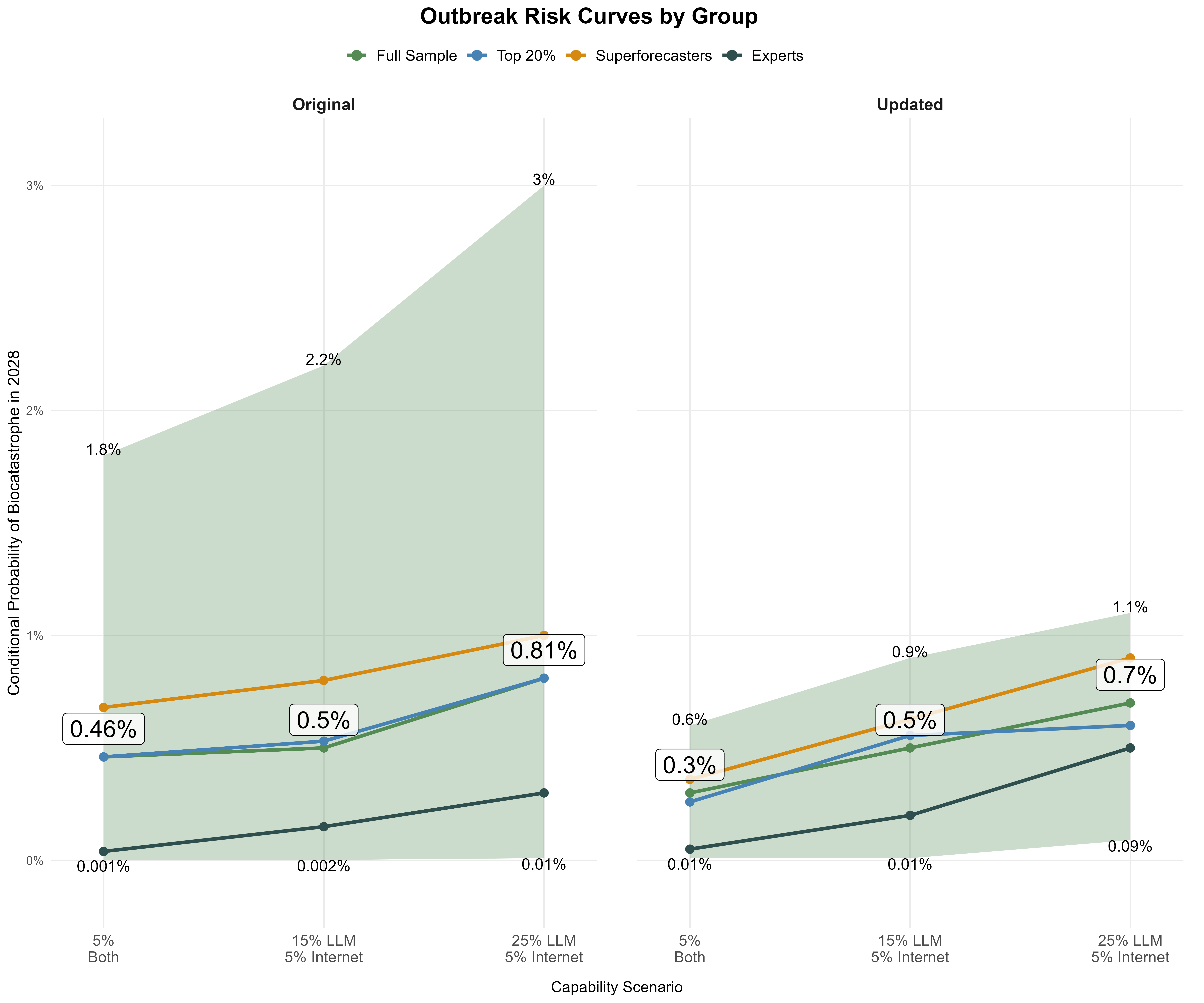
The resulting risk curves sloped upwards for all forecaster groups, indicating that participants perceived the RCT as a relevant signal of increased outbreak risk. For example, when assuming that a future RCT now finds that 25% of the LLM group succeed at the core tasks, while still only 5% in the internet-only group do, (i.e., a five-fold biological skill uplift due to LLMs), the median outbreak risk forecast increased from 0.3% to 0.7% (i.e., a two-fold risk increase relative to before).7 Notably, we saw substantially narrower interquartile ranges on the resurvey, suggesting that seeing ground truth from the RCT and each other’s predictions led to greater consensus among forecasters about biorisk.
How likely is it that we might see such LLM-enabled wet lab skill uplift? We asked forecasters to predict the results of future repetitions of the RCT on both the initial survey and the resurvey. Most participants adjusted their LLM-group forecasts downwards after learning the 2025 results but still expected LLM success rates to increase over time. They predicted a median LLM-group success rate of 7% (25th percentile: 6%, 75th percentile: 7.5%) if the RCT were repeated in 2026 which increased incrementally to 11% (25th percentile: 8%, 75th percentile: 15%) if it were repeated in 2030. If such an RCT is repeated, we will be interested to see how these forecasts compare—and if this might differ from how we have seen benchmark performance outpacing most forecasters’ near-term expectations.
Key takeaways
Forecasters overestimated the assistance that mid-2025 LLMs would provide to novices attempting to complete three wet lab tasks that are necessary to reconstruct a virus.
The median forecaster predicted a 12% success rate for the internet-only condition and 27% for LLM and internet access, compared to the actual results of 6.6% and 5.2%, respectively.
Those with a strong forecasting track record made more accurate forecasts than domain experts.
As a group, superforecasters produced the most accurate RCT forecasts. Despite deep technical knowledge of wet lab work, virologists performed the worst out of the three groups.
This may suggest that forecasting expertise is more helpful than domain expertise at predicting RCT results, but we cannot draw definitive conclusions from a single, somewhat noisy result.
The median forecaster predicted a baseline risk of 0.3% for a large-scale human-caused outbreak in 2028 in the original survey, and updated to 0.2% after the results of the RCT were revealed.
Among those who forecasted the RCT result most accurately, the outbreak risk forecast was 0.18% on the original survey and 0.10% on the resurvey.
Risk estimates increased meaningfully when forecasters assumed higher novice wet lab capabilities than those found in the Active Site RCT.
When asked to assume that LLM access leads to five times higher success at wet lab tasks, respondents’ median outbreak risk forecast increased two-fold.
Forecasters see a relationship between the RCT outcomes and outbreak risk, though it is weaker than the connection between RCT outcomes and virus rescue.
Forecasts of outbreak risk increased as forecasters assumed higher hypothetical RCT success rates. When asked to assume that the RCT showed that 50% of participants succeeded at core lab tasks, the median forecaster gave a 1.3% outbreak risk forecast, compared to 0.3% when only 5% succeeded at core lab tasks.
Median outbreak risk forecasts decreased after the RCT success rates (which were lower than most forecasters expected) were revealed, with the median risk forecast changing from 0.3% to 0.2% (among the sample that took part in both phases of the survey). These changes were notably smaller than the decrease applied to forecasts of novices’ capability to complete a virus rescue protocol.
Our definition of "human-caused" covers both accidental (e.g. "lab-leak") and intentional releases of a pathogen.
Independent samples t-tests compared each group to the rest of the sample on the two RCT outcome forecasts with the following results: virologists’ predictions versus the rest of the sample on the LLM + Internet condition (40% vs 20%, p=0.065) and Internet-only condition (30% vs 10%, p=0.179); superforecasters’ predictions versus domain experts (virologists and biosecurity experts combined) on internet-only condition (8.2% v 20%, p=0.727) and the LLM + Internet condition (16.2% v 40%, p=0.239).
Across more than 75% of bootstrap iterations, superforecasters have the lowest median forecast of both experimental groups, followed by biosecurity experts, followed by virology experts, preserving the ordering seen in the actual results despite sampling variation.
We identified those with the most accurate RCT forecasts by ranking respondents’ s-scores across 12 evaluable questions with known outcomes. S-scores are scoring rules for quantile forecasts that reward accurate and informative predictions. The top 20% threshold comprised 15 respondents (10 superforecasters and 5 biosecurity experts). The choice of top 20%, in particular, is arbitrary, though we experimented with other thresholds. We settled on 20% as the right balance of increased sample size and ensuring the “top” group’s forecasts were notably different from those of the full samples’.
This differs from the 0.2% cited in figure 3 as it is the median of the 65 forecasters who took the resurvey, not the full sample of 77 forecasters who took the initial survey.
Forecasters were asked to consider a study that replicated the design, tasks, and sample size of the 2025 Active Site RCT, but used updated LLMs.
Similarly, in a separate question, most participants also thought that success in the RCT tasks was strongly correlated with the ability to construct an influenza virus. In other words, respondents predict that increased performance on the core tasks over eight weeks, as tested by the Active Site RCT, would be strongly associated with more novices succeeding at a full end-to-end virus rescue protocol over several months.