

What Experts and Superforecasters Think About the Future of AI Research and Development
In Wave 4 of the Longitudinal Expert AI Panel, we asked for predictions on AI R&D, technology company valuations and hiring, hyperscale infrastructure building, and more.

Wave 4 of the Longitudinal Expert AI Panel (LEAP) asked panelists to forecast how the rising use of artificial intelligence will affect AI-related research and development and how this may impact leading AI and technology companies. Some experts believe that AI-driven improvements in the development of AI systems will lead to an explosion of AI capabilities. We designed this wave of forecasting questions to elicit forecasts about that mechanism.
Every month, LEAP tracks the views of top AI scientists, industry leaders, policy researchers, economists, and superforecasters on the trajectory of the development and use of artificial intelligence. As our chief scientist, Phil Tetlock, wrote in a recent essay for Bloomberg, the aim of LEAP is to provide the debate regarding the future of AI with precise, policy-relevant predictions rather than overconfident proclamations.
This post covers key highlights from the Wave 4 LEAP survey that we conducted between November 20 and December 20, 2025. Full details of this wave, including question details and analysis of rationales, are available here. For more information on earlier LEAP waves, read our launch blog or white paper.
Insight 1: AI model benchmark performance outpaced most forecasters’ near-term expectations
AI performance on hard coding tasks is a useful indicator of potential capability increases in self-improving AI R&D: where models take an active role in improving AI itself.
LEAP panelists gave their predictions of state-of-the-art (SOTA) accuracy on LiveCodeBench Pro (Hard), which is a benchmark that tracks performance on tough programming tasks. The median expert in our sample predicted SOTA accuracy of 14% in 2026 and an increase in accuracy to 33% by the end of 2030.
Recent benchmark performances suggest that the median expert is substantially underestimating the progress of development of SOTA AI systems. Since the survey closed, OpenAI’s GPT-5.2 achieved 33% accuracy on the Q3 2025 set of problems on LiveCodeBench Pro. While the set of questions on the platform is dynamic, and future performance on question sets may be lower than 33%, the resolution of this question will be at least 33%.
Experts’ underestimation of benchmark progress is also evident in earlier work from FRI. In a paper released in September 2025, we found that domain experts and superforecasters underestimated AI progress across the MATH, MMLU, and QuaLITY benchmarks.
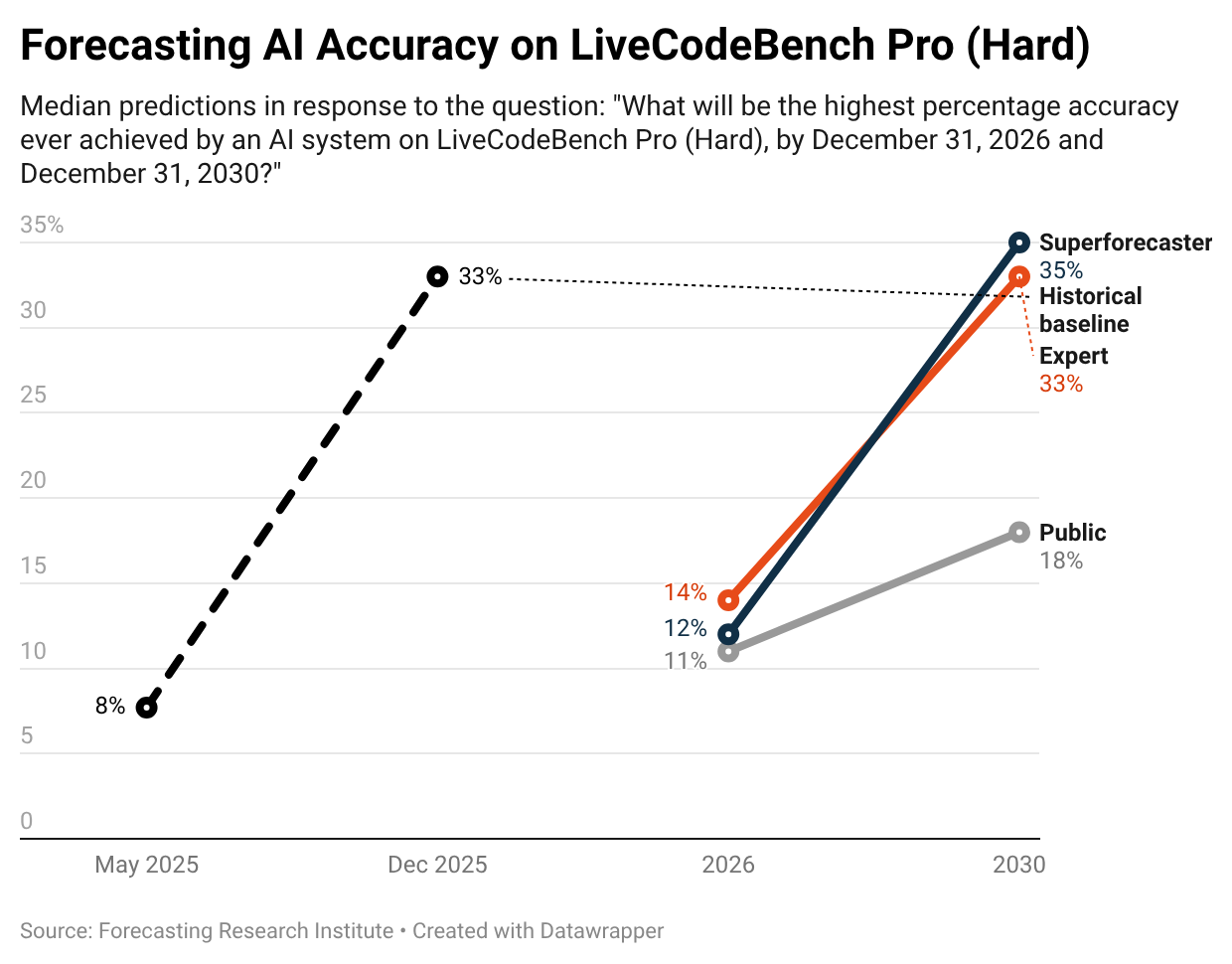
Despite the low median forecasts, LEAP panelists still substantially disagreed with each other. For example, the top quartile of superforecasters predict at least 60% SOTA accuracy on LiveCodeBench Pro (Hard) by 2030. We are excited to identify the forecasters who were most accurate on questions like this to see what they believe about other topics.
Insight 2: Experts predict continual low levels of junior hiring, and some rationales point to AI being a driver of this outcome
We asked panelists to forecast the percentage of new hires at the top 15 tech companies with up to one year of experience in 2026, 2030, and 2040. The median expert expects this share to remain close to its current low of seven percent through 2040. This predicted share is well short of the 15% of hires seen in 2019 and 2023.
Experts and superforecasters give largely similar forecasts, but superforecasters expect stronger entry-level hiring by the end of 2040 than experts: superforecasters predict that 10% of new hires will be entry-level in the median end-of-2040 scenario, compared to the median expert’s central forecast of 7.8%.
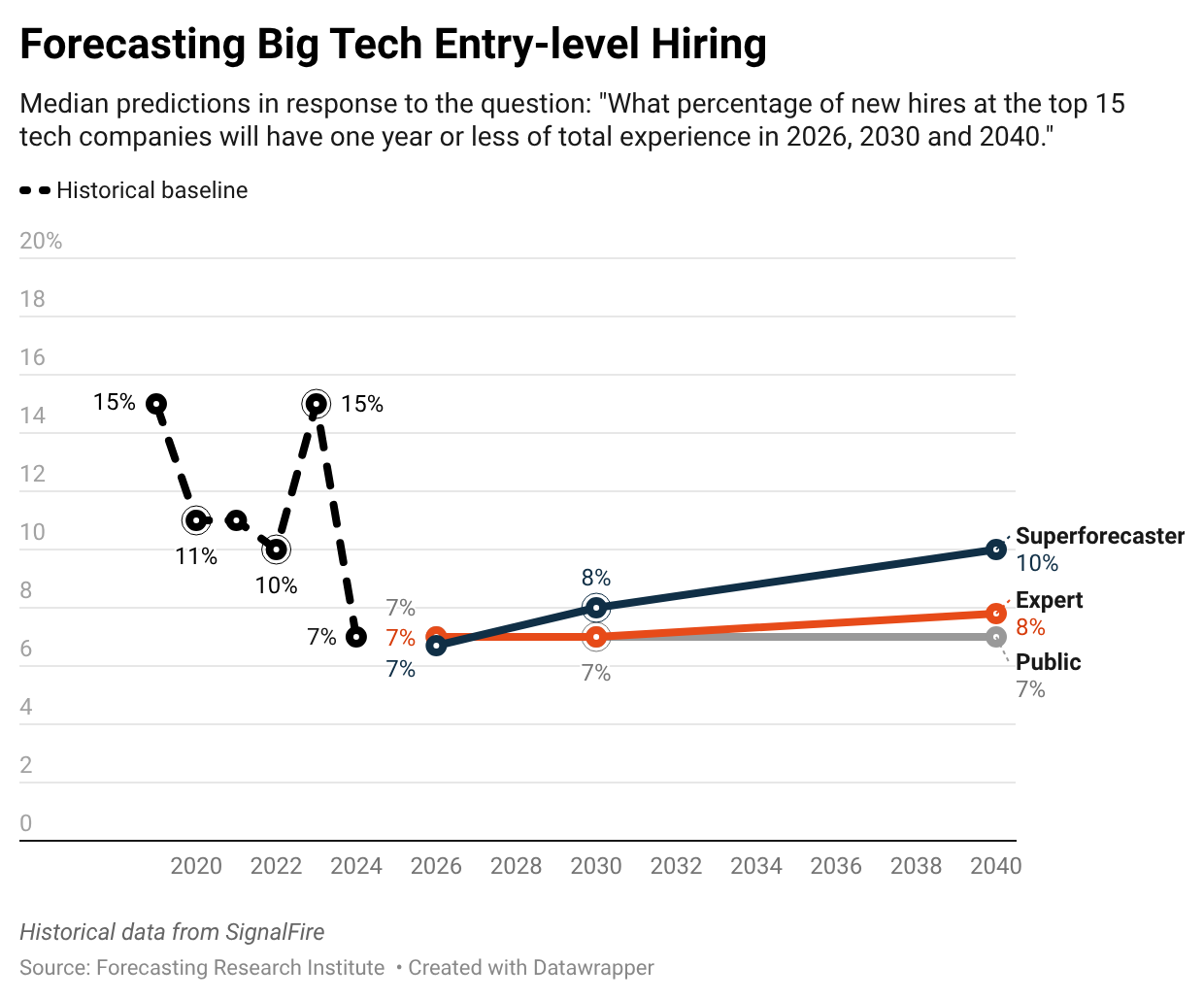
Some respondents pointed to AI as a driver of continued low rates of entry-level hiring. For example, one forecaster wrote that “[t]he risk for entry-level hiring skews to the low end of the distribution as it will be plausible to use a combination of contractor-outsourcing and LLM/AI tools to skew a company’s workforce towards mid-level employees.” Other forecasters pointed to macroeconomic factors that may influence the share of entry-level hires rather than AI progress.
Insight 3: Experts expect AI and technology companies to become more valuable per employee
The median expert predicts that by the end of 2030, the valuation-per-employee for top AI companies will grow to $20 million; this is about a 40 percent increase over the Q3 2025 baseline of $14.2 million. By the end of 2040, the median expert’s central forecast rises to $32 million. However, experts express uncertainty in their forecasts. The median expert assigns a 25% likelihood that the valuation-per-employee ratio in 2026 will fall to $13 million or less and a further 25% likelihood that the ratio will increase to $21 million or more.
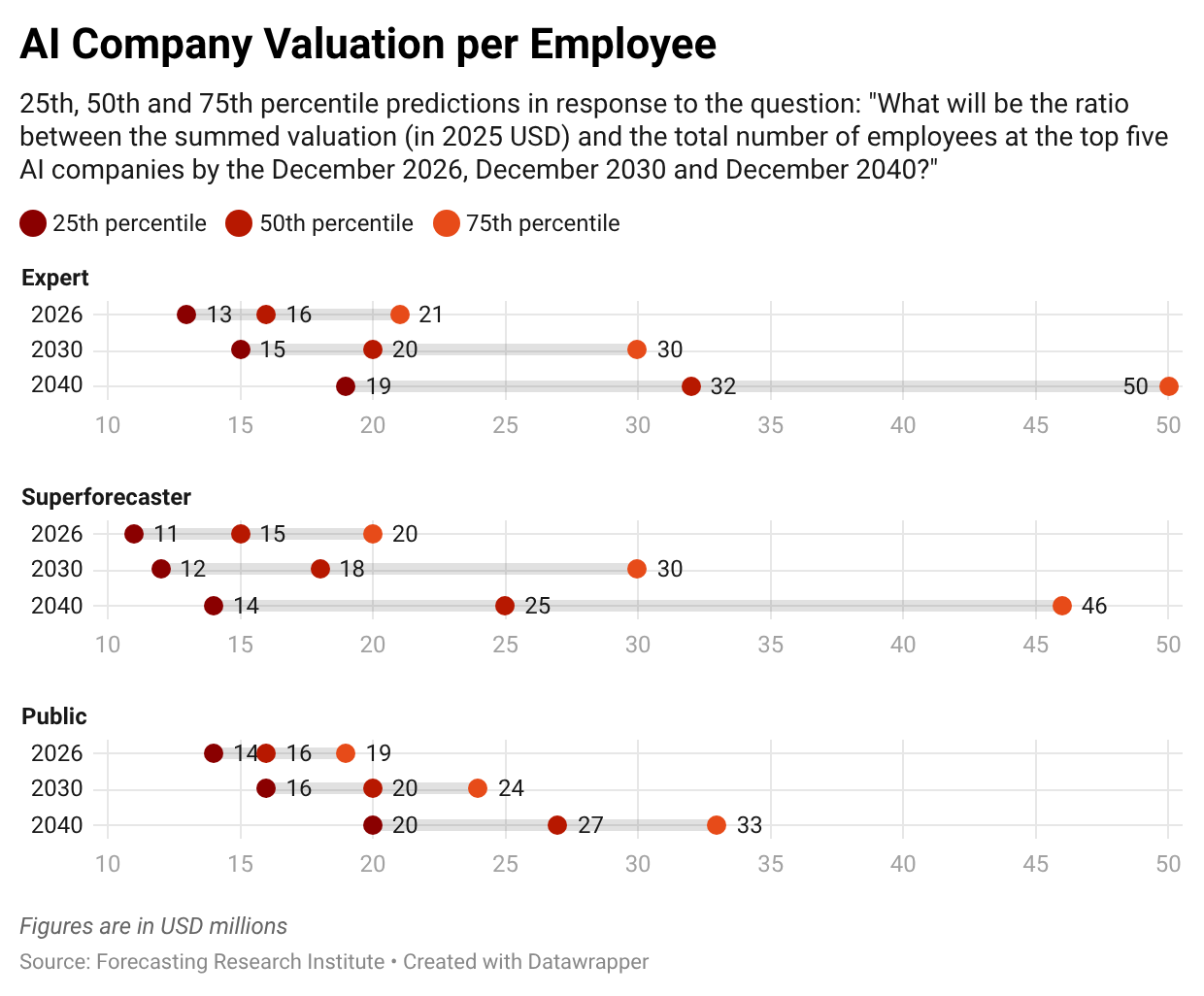
We also asked forecasters to predict the calendar year in which at least three companies with five or fewer full-time employees first report individual valuations of $10 billion (in 2025 USD) or more. The median expert gives a 50% chance of resolution by the end of 2032, the public by the end of 2031, and superforecasters by the end of 2033. The median forecaster in all three groups gives a 5% chance that three such companies will exist by the end of 2027.
Some public figures have opined on a similar question. OpenAI CEO Sam Altman has publicly stated that “[w]e’re going to see ten-person, billion-dollar companies pretty soon.” Economist Tyler Cowen, in an interview with Altman, predicted “I think you’ll have billion-dollar companies run by two or three people with AIs, I don’t know, two-and-a-half years.” Altman responded, “I agree on all of those counts. I think the AI can do it sooner than that.”
Insight 4: Experts forecast major increases in AI data center buildout
We asked our panelists to predict the total installed capacity (in gigawatts) of hyperscale data centers operating globally by 2026, 2027, and 2030. We follow the International Energy Agency’s (IEA) definition of hyperscale data centers as having 100 MW of capacity—that is, they consume as much electricity annually as 100,000 households. The IEA estimates that the total installed global capacity of hyperscale data centers in 2024 reached 36 GW.
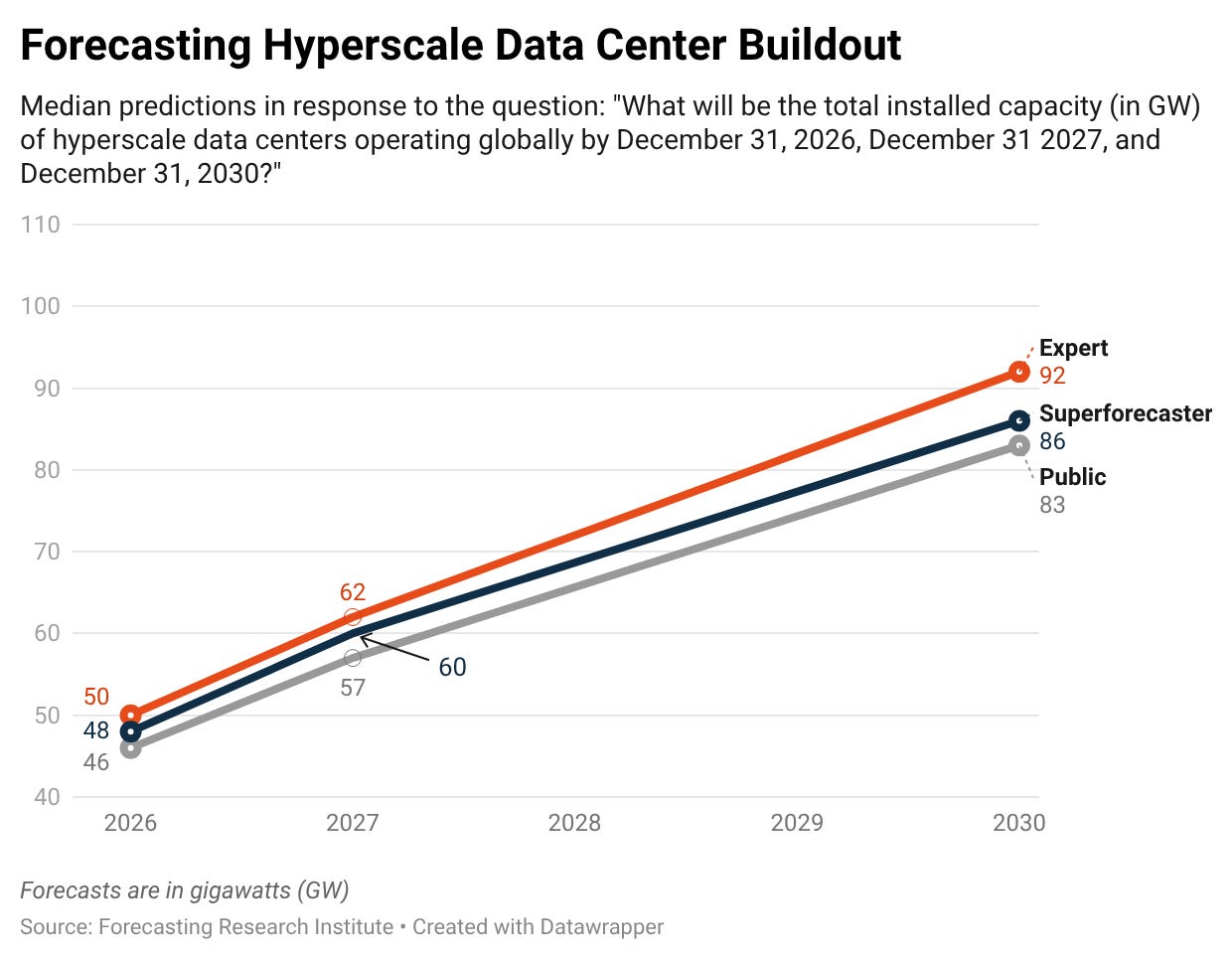
The median expert’s central forecast of 92 GW of installed capacity by the end of 2030 is a 2.6x increase from the 2024 level and aligns with IEA projections of 62–108 GW of installed capacity by the end of 2030. Other groups give slightly lower forecasts than experts: the public predicts 83 GW and superforecasters predict 86 GW. Experts’ and superforecasters’ central forecasts for 2030, however, are statistically indistinguishable.
Insight 5: Experts and superforecasters tend to forecast similar levels of progress, but when the two groups disagree, experts tend to predict more progress than superforecasters
As we observed in previous LEAP waves, experts and superforecasters tend to forecast similar levels of progress across most questions. However, even when forecasters agree directionally on the impacts of AI, written rationales reveal deep disagreements about the reasons for their forecasts. Some forecasters argue that high valuations and the rapid buildout of data centers are the result of bubble dynamics. Others argue that improvement in AI agents will lead companies to dramatically increase their revenues without increasing the size of their workforces.
Find out more about LEAP
To read more about Wave 4 of LEAP, including further questions and rationale analysis, visit the LEAP website. If you have a suggestion for a question you’d like to see covered in a future LEAP wave, please submit a question through our online form.
At the time of the question, the top four models on LiveCodeBench Pro Hard were the only ones with a single correct resolution in the 15-problem subset. Yet, they were not achieving this on the same problem, and collectively they solved three problems and scored 3/15 (20%).
While it's certainly a significant improvement that GPT-5.2 solved 5, it added just 2 more to the total, suggesting that the relative improvement in overall AI capabilities is not as large as one would guess by looking at the individual benchmark performance.